Tips on turning a Microsoft SQL query into a HTML report within an Azure DevOps pipeline. Not the fanciest new tech, but the boring stuff is often where the real work happens.
The Method
We want to run some SQL in a repeatable, friendly way. That is, without giving everyone SQL credentials, instructing them to open up a SQL prompt and run a specific query. A risky business at the best of times.
If you need a repeatable series of tasks programmatically completed you can probably use a pipeline, and that’s exactly the plan here. We are going to join two tools: isql and the Publish HTML plugin for Azure DevOps. Here’s an example created earlier:
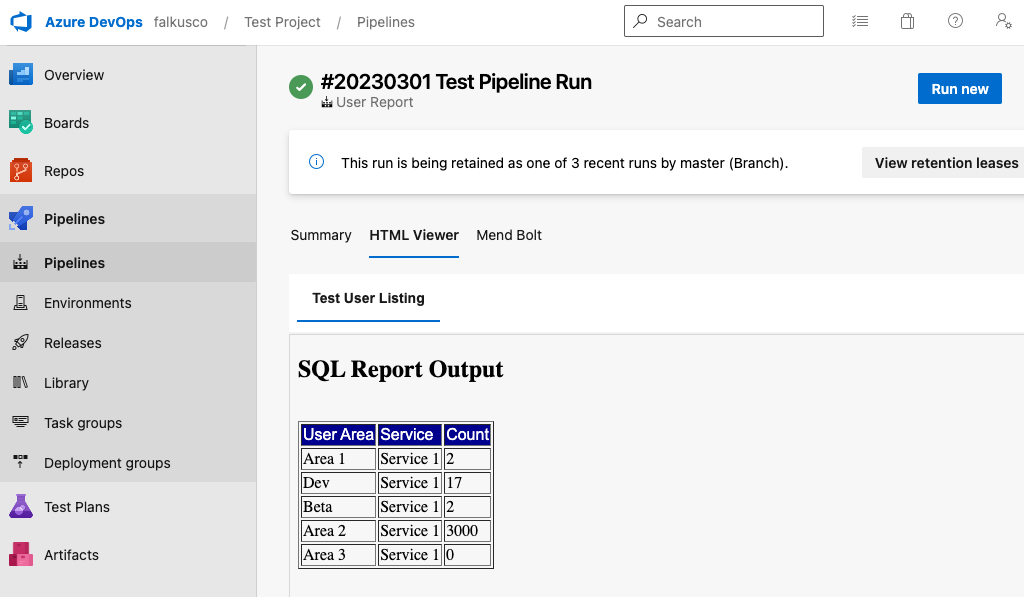
From SQL query to HTML within a pipeline. Great success.
Data First
isql is part of unixODBC and has been since 1999. This is good as it means it’s super likely to be available in whatever flavor of Linux you’re using. It’s going to let us run SQL from the command line. Particularly of interest to us is the option for outputting the results as a HTML table.
You can use the normal script capability within Azure DevOps, e.g.:
- script: |
cat query.sql | isql mydb $(DB_USERNAME) $(DB_PASSWORD) -n -w -b >> '$(Common.TestResultsDirectory)/Report.html'
displayName: 'Run query and output results to HTML'
The required -n -w -b command line arguments are explained later.
Display Results
PublishHTMLReports is a plugin for Azure Devops that will give us a HTML tab once the pipeline has finished running. Without this we could only make a build artifact, which would then require the user running the pipeline to download and open up a results file. Hassle.
The plugin is aimed more at those wanting to display test suite results, but we can use it for whatever HTML we like, e.g.:
- task: PublishHtmlReport@1
displayName: 'Publish HTML Data Output'
inputs:
reportDir: '$(Common.TestResultsDirectory)/Report.html'
tabName: 'Query Output'
On a high level, that’s it! However on a detailed level, there are various things to look out for, specifically with isql…
Various Gotchas…
The ‘i’ stands for interactive, but you probably don’t want interactive if you’re running in a pipeline. Fortunately it has a batch mode:
-b Run 'isql' in non-interactive batch mode. In this mode, 'isql' processes from standard input, expecting one SQL command per line.
Emphasis above is mine. What if we have some non trivial SQL? Putting the whole thing on a single line is going to be awkward to maintain. Fortunately we have a multi line option:
-n Process multiple lines of SQL, terminated with the GO command.
The multi line support will run each SQL line separately.
go; must be on its own line at the end of the file (and the semi colon is
important).
For complex SQL this probably isn’t what you want.
e.g. if you’re declaring a SQL variable
then using it later, that’s not going to work. For cases such as that only the final
go; line should have a semi colon and all the other lines must not.
-w Format the result as an HTML table.
An example output from a query that gives back a single column/row. The styling is a freebie from the 90s:
<table BORDER>
<tr BGCOLOR=#000099>
<td>
<font face=Arial,Helvetica><font color=#FFFFFF>
MyColCount
</font></font>
</td>
</tr>
<tr>
<td>
<font face=Arial,Helvetica>
0</font>
</td>
</tr>
</table>
- You’ll need to name your dynamic columns, e.g.
count(*)won’t have a heading in the HTML output, butcount(*) as MyColCountwill. - You are getting back a HTML segment. This is actually quite desirable as
it is easy to write out some HTML ahead of this with improved styles or extra
information, then
just append to that in your pipeline, e.g.
cat my-sql.sql | isql -w >> already-styled-page.html. Although it’s fine not to do this, a browser will still be able to make sense of the HTML segment on its own.
Whilst you’re trying all this on the command line ahead of actually running
in a pipeline you probably want to include -v. Without it you won’t
get any error output if the query fails.
A final pointer, it’s worth getting familiar with a couple of ODBC configuration
files. Firstly /etc/odbc.ini, you can use
this to preconfigure access information for servers/databases (not
credentials). Secondly, /etc/odbcinst.ini, as you can set Trace within
this file which will give you more detailed debugging output than you could ever
imagine. This is probably the place to head next if you’ve tried -v in isql
and still can’t get things working as expected, just remember to turn it off
when you’re done.