Taking monkey patching to the next level: Crazy ways to deploy code to production.
The term Monkey Patching is likely somewhat familiar to most developers as a way to describe quick-and-dirty software fixes.
The word guerrilla, nearly homophonous with gorilla, became monkey, possibly to make the patch sound less intimidating.
Monkey Patching Wikipedia Page
I think this can be expanded to three types of unusual patching…
- Monkey Patching - Rare but not super crazy
- Gorilla Patching - Desperate times, desperate measures
- Grizzly Bear Patching - A fix that is completely off the deep end
We need diagrams and a starting point. Here is an example normal developer to production work flow…
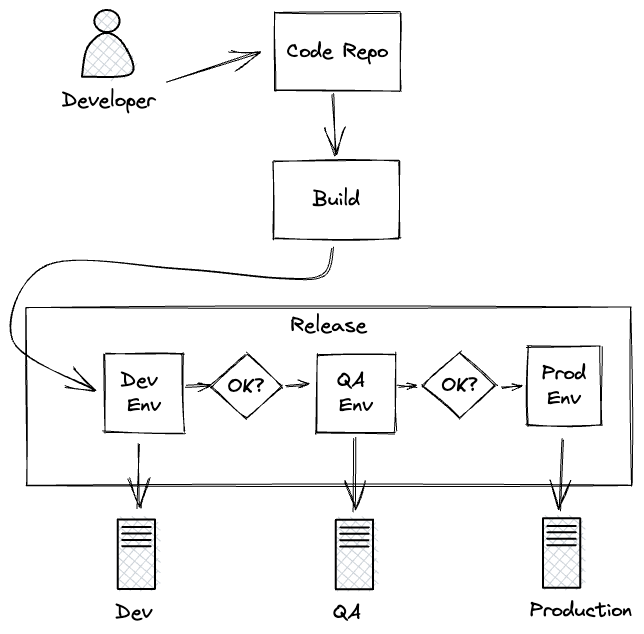
A relatively normal development flow
1. Monkey Patching
Shortcut all the usual testing and review process to make a rogue build. Perhaps you push direct to master, or skip some QA environment stage, but whatever the process, the build created doesn’t go through the expected normal way.
The production release pipeline is still followed meaning there should be a clear paper trail of the unusual production state.
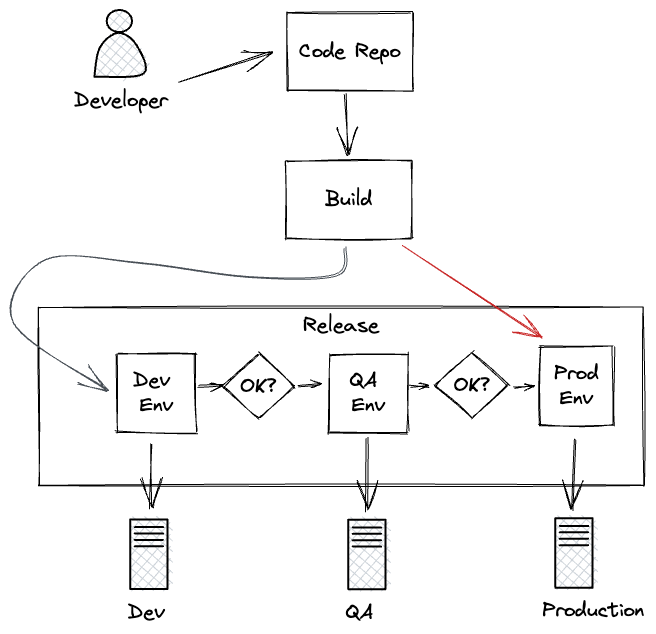
Monkey patching here is skipping some of the early quality checks and environments.
2. Gorilla patching
Let’s kick it up a level.
Don’t have time to git push and wait for a remote build and release? Gorilla
patching could be for you.
This is directly making an edit in production. If you run your code as a binary
shipped to a virtual machine, you are shipping a new binary directly. If it
is a scripting language perhaps you are sshing to a remote box and directly
editing a file.
There is no evidence in the build and release pipeline history of your changes,
but .bash_history and auditd flag it up. Perhaps you’ve got some integrity
checks on the machine as well alerting that code files have been modified.
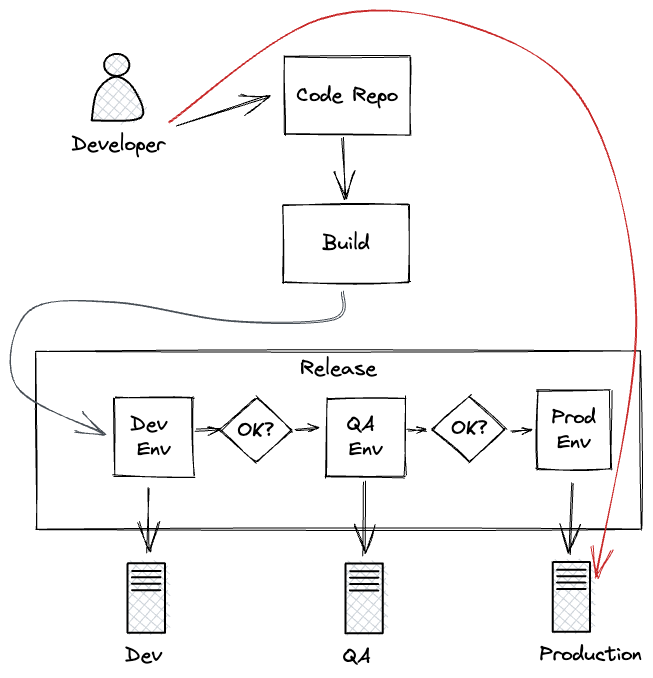
Gorilla patching jumps straight to production instances. No release pipeline required.
3. Grizzly Bear Patching
So ridiculous I am not even sure this counts as patching code. I had to even add elements to my diagram below.
The idea is that you are literally acting as production in your local environment. This could be something async, e.g. you run a service on your local laptop and connect it to the production service bus. Or it could be more directly customer facing, e.g. you alter your infrastructure DNS to point to your local machine rather than your production web server or load balancer. Scary stuff.
Very little paper trail here.
I’m not sure I’ve heard of this being done in the wild but someone must have it done it at some point with a reason. If you have a story about this type of thing I’d love to hear it. Send it anonymously if you like.
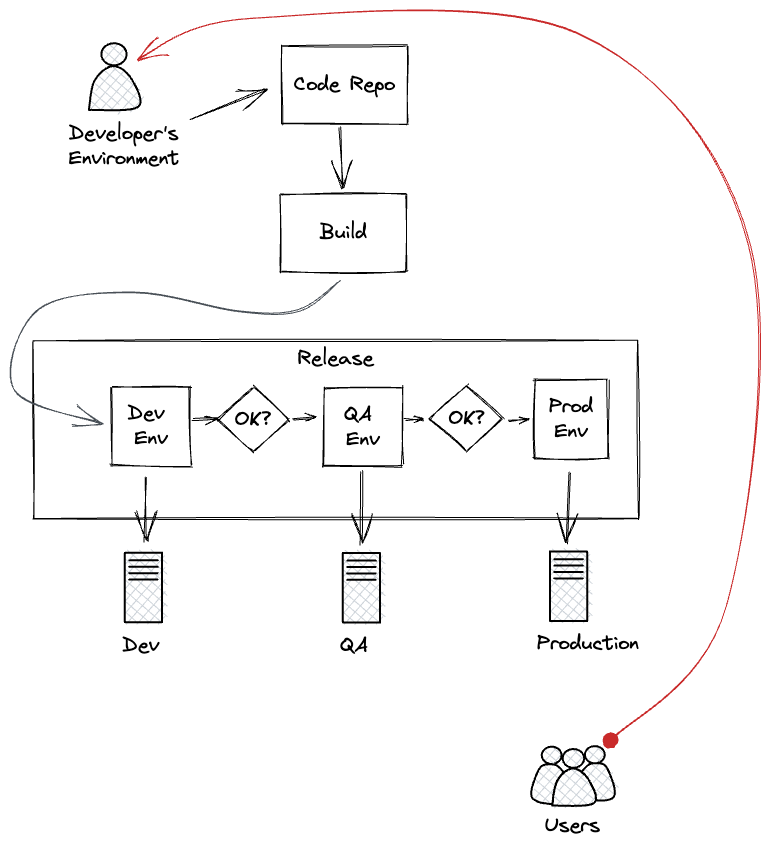
Grizzly Bear Patching: making production point at a completely different environment, bypassing everything about the normal process and infrastructure.
More Crazy?
Are there even crazier ways to deploy code? I can’t immediately think of anything more crazy than pointing your production DNS at some developer’s laptop but I’m open to suggestions!
Finer Grain
We could possibly split further with hot/cold versions of the above, where hot means the restart of the service was immediate, the fix just couldn’t wait. Cold fix would be the fix is there and waits a safe period to be swapped in (e.g. out of hours maintenance restart or similar).